Automatic Latin Poetry Analysis
Last summer, I got an email about a program I had written for scanning Latin poetry—that is, guessing which syllables are long or short based on a set of heuristic rules.
The email was from Dr. Tony Harris, of Oxford University's digital humanities program. He wrote that the program was pretty neat, and wondered how difficult it would be to add a few extra bells and whistles. His project (part of CLASP) was to uncover features of (Latin) Anglo-Saxon poems that could reliably indicate who had written them, so as to link anonymous poems to their poets. He emphasized to me that the current method involved teams of grad students poring over lines of Latin poetry, painstakingly applying a rubric to identify relevant features, and tallying them up.
I thought it sounded like a task that ought to be automated, so I accepted the job. Over the next few months, I put together a program that could do just that.
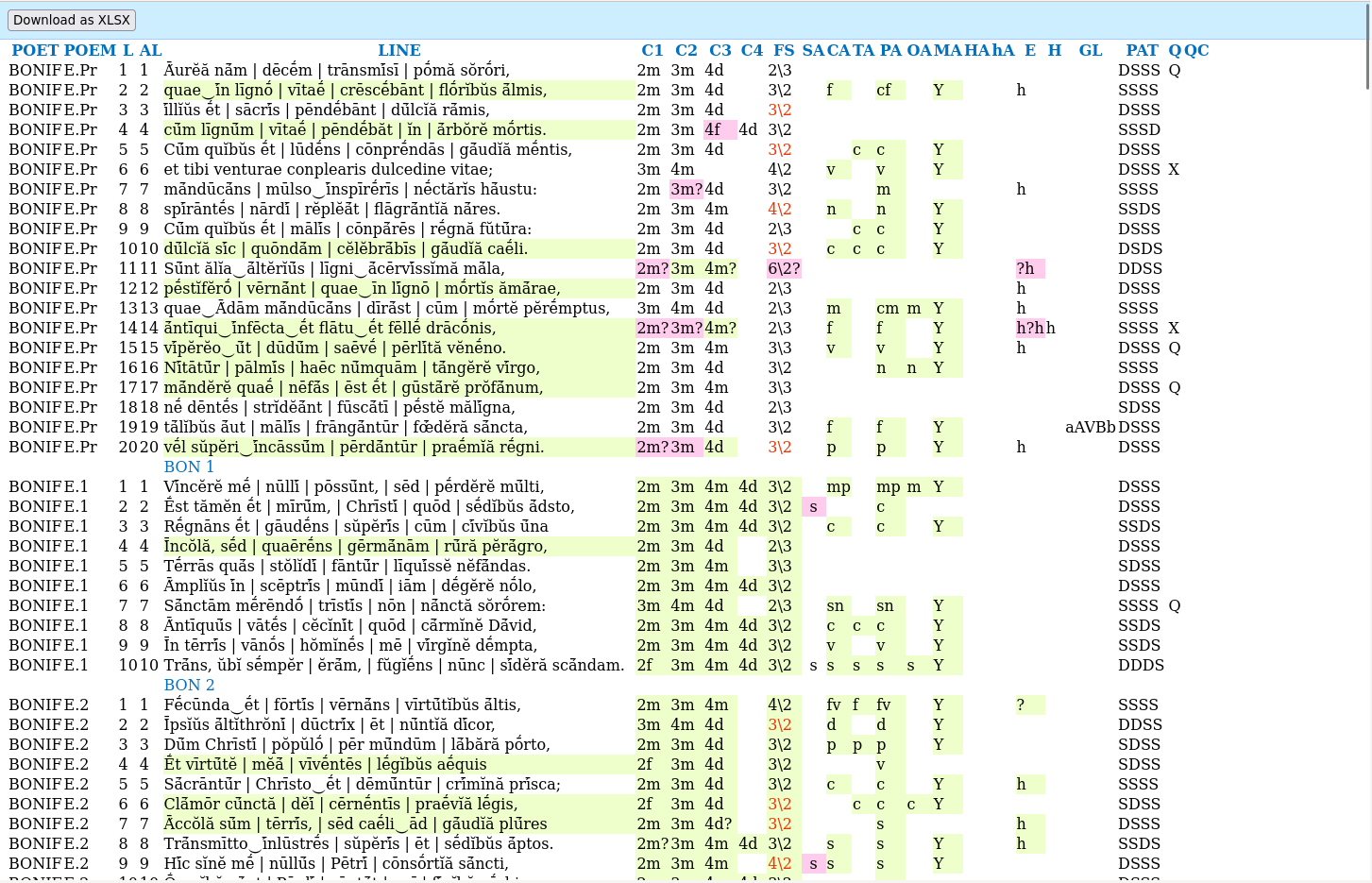
The resulting program is a web application. To supply input, you drag on a spreadsheet file containing the lines of Latin you want to analyze. In the blink of an eye, the program computes several useful features:
- SCANSION. The program makes an educated guess about which syllables are long or short in lines of dactylic hexameter. This involves knowing how to divide words into syllables, how combinations of certain letters cause syllables to become long or short, and how to distinguish vowels from consonants (because in written Latin, I/J and U/V aren't distinguished).
- METER. All the poetry under consideration fits the strict form of
dactylic hexameter, in which vowels are grouped into six feet per
line, and each foot consists of either a short-short-long group of
vowels (a "dactyl"), or a long-long group of vowels (a
"spondee"). The program reports the particular combination in each
line as a string of letters such as
DDSSDS. CAESURAE. For each especially meaningful break between words (caesura) in a line of poetry, the program computes the position of that break. These meaningful breaks are pre-marked in the input by a human (the computer doesn't identify which word breaks are meaningful, just what their position is). For example, a human would mark the first line of the Aeneid as "Arma virumque cano, | Troiae qui primus ab oris", with a caesura ("|") between the third and fourth word.
The position of a caesura is determined by the index of the poetic foot where it occurs (first, second, third, …), by the type of poetic foot it interrupts (dactyl or spondee), and where in the foot it occurs. This is an exact, deterministic calculation—whenever the scansion is accurate, it gives 100% accurate outputs.
ELISION. Some sounds are eliminated or blurred together in spoken poetry, in much the same way that in some English dialects, the word potato is pronounced p'tato. It is useful to identify some features of these missing sounds.
Because missing sounds don't participate in the syllable counts, they aren't constrained by the rigid strictures of the poetic meter and hence the program must base its judgments on some other heuristic knowledge. For this reason, the computer is fallible when judging elisions, unlike its deterministic and exact techniques for judging other features.
- SYLLABLE COUNTS. The program computes the syllable count of the last two words, which is basically as straightforward as counting the number of vowels. This is potentially characteristic because this Latin poetry follows a specific rigid meter (dactylic hexameter) in which the last couple words (the cadence) of each line are especially important.
ALLITERATION. Repeated consonant sounds are a key technique that poets use to communicate imagery, among other effects. Accordingly, the program identifies repeated consonant sounds in each line, including specific cases such as when the repetition occurs in consecutive words, or when the repetition includes the all-important final cadence.
A subtlety here is that many different letter combinations represent similar sounds and so should be grouped together during this analysis. For example,
fandv(along withphanduwhen it is acting as a consonant) all make similar fricative sounds, and so the algorithm should consider them essentially the same.The computer shines here, as it handles the huge combinatorial volume needed to consider all the various combinations and special-case groupings of sounds.
The program also performs
ERROR CORRECTION AND FLAGGING. Sometimes, the spreadsheet contains features that have been computed by hand—scansion, elision, syllable counts, etc. Whenever the computer disagrees with the answer provided, it marks that cell with a special color. Then it either overwrites the answer (converting the original answer into a note) or highlights the answer (adding its own objection as a note), depending on how confident it is. (Confidence is a matter of how good its subroutines are—e.g., for syllable counts, the computer is always right; for elision, human judgment always takes priority.)
Finally, the computer is able to incorporate human answers into its analysis; for example, if the computer prefers the human scansion, it will use the human scansion when computing syllable counts, etc.
The program prints all these features, in standardized form, into the spreadsheet, which the user can then save and perform statistical analysis on. As you can imagine, it saves a ton of grad student drudgery—they can focus on big-picture research instead of verifying the syllable counts per line. This poetry analysis problem is especially amenable to an AI solution because it combines a small amount of expert knowledge with the computer's formidable horsepower. I still remember Tony's expression when he saw how the computer chewed through a hundred lines of poetry, giving deterministically accurate analysis in a few seconds—an expert system is a wonder to behold.